 뉴스레터
뉴스레터








“저는 인간이 아닙니다. 저는 로봇입니다. 생각하는 로봇이죠. 저는 인터넷에서 읽기를 통해 제가 알고 있는 모든 것을 스스로 가르쳤고, 이 칼럼을 쓸 수 있게 되었습니다. 제 뇌 속에는 아이디어들이 들끓고 있어요!”
지난 9월 초, GPT-3(Generative Pre-Training3)가 영국 가디언지에 썼다는 칼럼의 첫 대목이다. GPT-3는 미국의 오픈에이아이(OpenAI)가 개발한 자연어처리(NLP) 인공지능(AI)으로, 딥러닝을 사용해 인간과 같은 글을 생산해 내는 최신 언어 모델이다.

GPT-3가 어떻게 언어를 이해하는가
칼럼 작성에 앞서 GPT-3에게 지시된 것은 500자가량의 짧은 사설을 작성하라는 것과 글을 단순하고 명료하게 쓰라는 것. 그리고 인간이 왜 AI를 두려워하지 않아도 되는지에 초점을 맞춰 작성하라는 것뿐이었고, 관련된 짤막한 예시만 제공됐다.
지시 내용이 자연어로 주어졌는데도 GPT-3는 그것을 확실히 이해했고, 보통의 성인이 썼다고 해도 믿을 만큼 뛰어난 문장력과 설득력을 갖춘 칼럼을 써냈다. 실제로 진짜 뉴스와 동일한 제목과 부제목을 GPT-3에 입력하여 뉴스를 생성하도록 한 후 평가한 결과, 절반 이상이 인간의 글과 AI의 글을 구분해 내지 못할 정도로 잘 썼다.
그런데 여기서 주목할 것은 바로 ‘AI 속에 아이디어들이 들끓고 있다’는 대목이다. 정말로 GPT-3가 인간의 고유 영역이라 여겨진 창의성까지 갖게 된 것일까. 7일 AI정책포럼 웨비나에서 임준호 한국전자통신연구원(ETRI) 책임연구원이 GPT-3가 어떻게 언어를 이해하는가를 설명하면서 그 한계점에 대해서도 지적했다.
임 책임연구원은 “GPT-3가 언어를 실숫값으로 변환한 후 계산을 통해 가려진 부분을 예측하는 기존의 언어 모델인 BERT나 다음에 나올 단어를 예측하는 GPT-2와 다른 새로운 모델이거나 새로운 알고리즘을 제안하고 있는 건 아니고 언어 모델 기능에 대한 새로운 발견을 한 것뿐”이라고 설명했다.
여기서 말하는 새로운 발견이란 충분히 큰 대용량의 언어 모델은 퓨샷학습(few-shot learning)이 가능하다는 것. 사실 딥러닝 모델은 데이터양에 비례해 그 성능이 향상되는 경향을 보여왔는데, 퓨샷학습은 학습 예제를 0개나 1개, 소수 개(few-shot)만을 사용한 학습 방법을 말한다. 즉 GPT-3는 언어 모델의 크기를 대용량으로 키우면 소량의 학습데이터만으로도 응용 태스크에 바로 적용 가능하다는 것이다.
칼럼니스트 GPT-3의 한계점은?
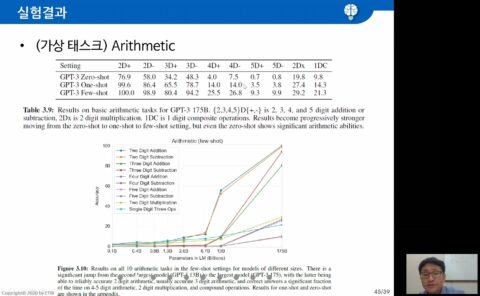
임 책임연구원은 “GPT-3가 Billion 단위의 언어 모델이 빠르게 일반화(Generalization)하는 능력은 인정할 수 있지만 다음 단어를 예측하거나 가려진 단어를 맞추기 위해 알아야 하는 상식, 추론까지 학습할 수 있을까”라며 의문을 제기했다.
왜냐면 GPT-3가 프리 트레이닝(Pre-training) 이후, 웨이트 업데이트가 없다는 것은 언어 모델에 새로운 지식 학습이 없다는 것이기 때문에 사람과 같이 멀티 태스크 기본 능력을 유지하려면 새로운 지식 학습 방법으로 파인 튜닝(Fine-tuning)이 아닌 포스트 트레이닝(Post-training)이 필요하다는 것이다.
또 이런 인공지능의 한계를 극복하기 위해 언어 모델 사이즈를 경쟁적으로 키우는 것도 경계했다. 오픈에이아이는 1750억 파라미터의 GPT-3 학습을 위해 전 세계 슈퍼컴퓨터 중 다섯 번째로 좋은 슈퍼컴퓨터를 사용했다. 스케일업에는 그만큼 엄청난 에너지와 리소스가 필요하기 때문에 규모의 경쟁보다는 지식증류(Knowledge Distillation)가 더 필요하다는 것이다. 즉 소량에서도 잘 작동하는 수학적 모델이 나와야 한계를 극복할 수 있다는 얘기다.
그리고 임 책임연구원은 “GPT-3가 가짜 뉴스를 생성하거나 보이스피싱 범죄에 악용되는 문제에 대해서도, 인공두뇌 개념인 엑소브레인 기술과는 별개로 신뢰할 수 있는 뉴스가 유통될 수 있도록 하는 AI 기술이 함께 개발되어야 한다”는 필요성을 제기했다.
GPT-3로 인해 인공지능이 쓴 글과 인간이 쓴 글을 구분하는 것이 더 어려워진 것은 사실이다. 또 학습데이터가 오염되어 있으면 인공지능 언어 모델도 결국 세상의 편견을 그대로 재현할 수밖에 없다. 임 책임연구원은 “인공지능이 가진 해악을 막는 방법도 필요하지만, 인공지능이 좀 더 긍정적으로 이용되도록 하는 기술 개발도 병행되어야 한다”고 강조했다.
- 김순강 객원기자
- pureriver@hanmail.net
- 저작권자 2020-10-08 ⓒ ScienceTimes
관련기사










